This working example below aims to gain useful heuristics through developing some insights from a new dataset through SQL. We will be using New York's 2022 Taxi Trips data from Google's public bigquery dataset for this illustration.
Perhaps some questions on this dataset that is of interest would be:
1. What were the most common trip distance taken by New Yorkers in a public taxi?
2. Were the fares per mile equal across different trip distances?
3. Which was the most popular pickup spot and destination?
Lets start of with some statistics of the trips data:
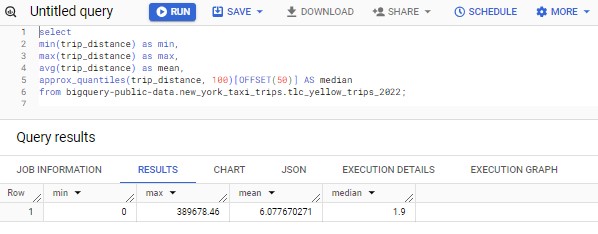

It would appear that there are extreme outlier values that are potential erroneous entries in the data as it is illogical for a taxi ride to be >300k miles but only for a fare of $12.11. Therefore, to simplify things, we will restrict the analysis of this dataset to be within a chosen arbitrary range of between 1 and 50 miles.
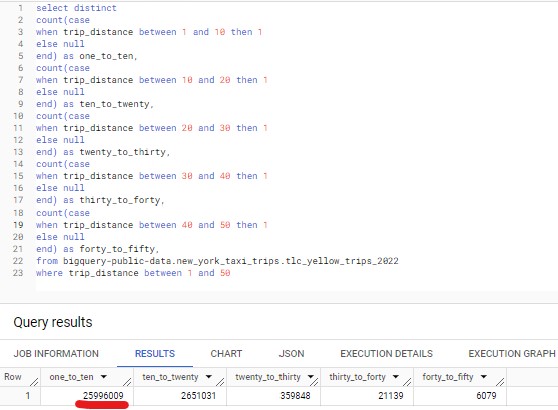
Question (1)
From the bucketed data above, it seems taxi trips between 1 and 10 miles are the most popular in New York 2022.
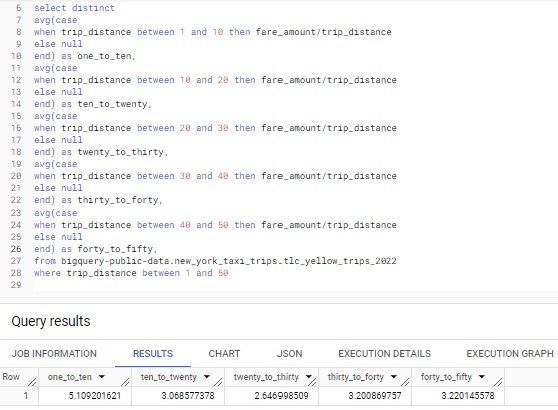
Question (2)
However, from the data below, not all trips are charged equally on a per mile basis as trips between 1 to 10 miles incur the highest fare per mile at an average of $5.1 compared to other longer trip distances.
Question (3)
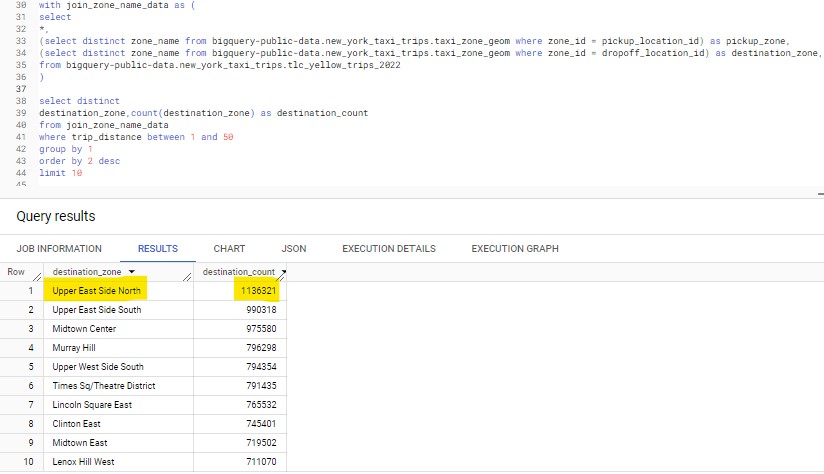
To conclude the 3rd data question, to find the most popular pickup/destination zones, we join the main dataset with the zone name data table below. The results shows that the most frequent pickup spot was JFK airport;
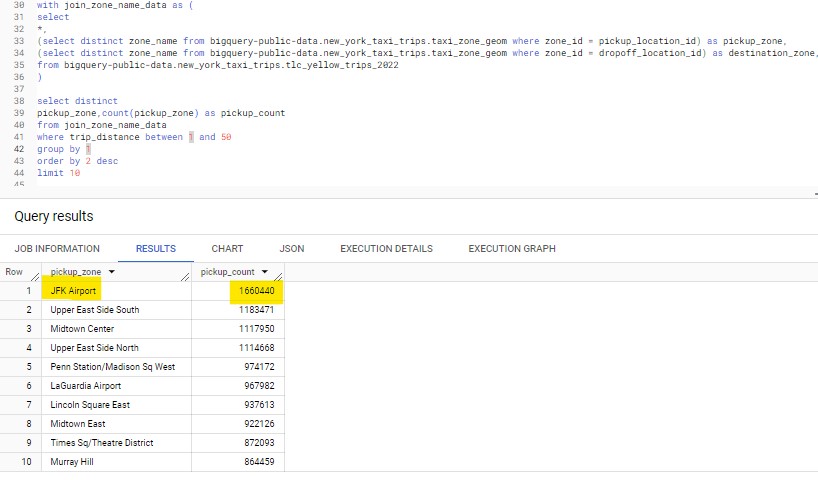
and the most popular destination was Upper East Side North.